What’s new in RAG?
As developers, staying up to date with the latest technologies is part of the job, and chances are, you’ve already heard of Retrieval-Augmented Generation (RAG). However, RAG has been evolving rapidly, with a growing number of research papers, tools, and experimental applications emerging every few months.

To catch up with these fast-moving developments, we’ve compiled a list of some of the most interesting advancements in RAG. Each item includes a brief description of what’s new and where you can find out more about this topic.
- Self-RAG / Corrective RAG
Large language models (LLMs) often produce factual inaccuracies when relying solely on their internal knowledge. While RAG helps mitigate this by incorporating external information, it has limitations. It typically retrieves a fixed number of context chunks and always uses them, even if they’re irrelevant. Self-RAG introduces a framework which enables the model to dynamically decide when to retrieve and whether to use the retrieved content, guided by special self-reflection tokens. These tokens allow the model to control its behavior during generation, such as triggering retrieval, evaluating the relevance of retrieved passages, or critiquing its own output.
The model can recognize when its answer is incomplete or unsupported, then either retrieve additional evidence or revise its response accordingly. This adaptive process helps reduce hallucinations and improves factual accuracy in real-time. Self-RAG: Learning to Retrieve, Generate and Critique through Self-Reflection - Graph RAG
Traditional RAG systems work well for answering clear, focused questions but have difficulty with questions that need understanding and combining information from multiple documents.
GraphRAG introduces a graph-based approach that combines the strengths of RAG and QFS (query-focused summarization). An LLM builds a two-stage graph index by extracting entities and their relationships from source documents to form an Entity Knowledge Graph and then creates Community Summaries by generating summaries for groups of closely connected entities. Given a user query, each community summary contributes a partial response, and these partial responses are summarized into a final answer.
This ensures that answers are well-supported by relevant information, reducing the risk of hallucinations and improving factual accuracy.
[2404.16130] From Local to Global: A Graph RAG Approach to Query-Focused Summarization - Chunk RAG
RAG systems often bring in irrelevant or loosely related information because retrieval operates at the document level. Instead of handling large documents all at once, this method breaks information into smaller pieces (chunks). This is done by splitting the data into sentences and grouping consecutive sentences based on cosine similarity. It stores and reuses these chunks smartly to save time and avoid redundant retrievals, which leads to faster and more efficient knowledge access. Moreover, techniques such as query rewriting, filtering of redundant chunks and relevance scoring reduce the number of hallucinations and increase factual accuracy.
[2410.19572] ChunkRAG: Novel LLM-Chunk Filtering Method for RAG Systems - HTML RAG
In typical RAG pipelines, web pages are retrieved in HTML, then converted into plain text. This process loses important structural and semantic information inherent in HTML (e.g. headings, table layout, hyperlinks, tags). On the other hand, raw HTML is very noisy and long. Much of it is non-semantic content, resulting in large token counts which exceeds many LLMs’ context windows. HtmlRAG proposes using HTML directly instead of plain text as the format for the retrieved knowledge, but with processing to make it manageable. The key concepts include HTML cleaning, block-tree construction over the HTML’s DOM tree, and two-step pruning of relevant blocks.
[2411.02959] HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems - Multimodal RAG
Traditional RAG systems are limited to processing text-based information. Multimodal RAG systems extend the RAG framework by integrating multiple data modalities – images, audio, most recent research also includes the integration of
video (https://arxiv.org/abs/2505.23990).
By incorporating multiple data types, these systems can provide more accurate and context-aware responses. Moreover, multimodal inputs enrich the generation process, enabling the creation of more engaging and informative content.
For those who’d like to delve deeper into recent progress with RAG, here are two advancements that caught our attention, explained in greater detail below.
Astute RAG
Retrieval-Augmented Generation (RAG) is enhancing large language models (LLMs) with external knowledge. However, real-world retrieval can often lead to irrelevant, incomplete and misleading documents retrieved, or even conflict with the model’s internal knowledge. This mismatch can lead to worse performance than using the LLM alone. This is especially common in specialized queries where retrieval precision drops.
Astute RAG, a framework proposed by Wang et al. (2025), focuses on robustness under imperfect retrieval and effective conflict resolution between internal and external knowledge.
The Problems Astute RAG Addresses
- Low-quality or noisy retrieval
Many RAG systems assume that retrieved passages contain the correct answer but in practice, up to 70% of retrieved passages may be irrelevant or incomplete. - Conflicts between internal and external knowledge
Even when retrievals are relevant, they may contradict the LLM’s internal knowledge. - Overreliance on external sources
Traditional RAG tends to treat retrieved content as absolute truth. Astute RAG challenges this by treating internal knowledge and retrievals as equals.
How Astute RAG Solves These Problems
Astute RAG introduces an architecture designed to adaptively incorporate, filter, and consolidate knowledge:
- Adaptive Internal Knowledge Elicitation
Before relying on external content, the system prompts the LLM to generate a context in response to the question based on its own internal knowledge. This internal context is included as an input alongside the retrieved documents. The LLM can generate a variable number of such passages based on its confidence. - Source-Aware Knowledge Consolidation
All knowledge (retrieved and internal) is assessed together. The system identifies conflicting, redundant, or irrelevant pieces of information and organizes them into coherent knowledge groups, while maintaining awareness of each passage’s origin (internal vs external). This step aims to resolve inconsistencies and filter out misleading or low-quality retrievals. - Answer Finalization via Comparative Reasoning
Rather than blindly aggregating all information, Astute RAG generates candidate answers from different knowledge groups and evaluates them through internal reasoning. The final output is selected based on consistency, reliability, and source trustworthiness, giving the model the ability to „prefer“ one source over another when conflicts arise.
The visual representation of ASTUTE RAG can be found in the following figure from the original paper:
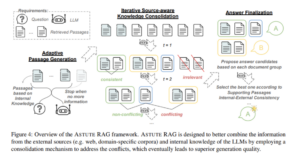
To dive deeper into this research, read more at [2410.07176] Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models
Agentic and Multi-Agent RAG
The simplest RAG pipeline is straightforward – retrieve relevant documents, feed them to a language model and generate an answer. However, for tasks that require complex reasoning or decision-making we might benefit from more adaptive and robust RAG systems. One promising direction is Agentic RAG (also known as Multi-Agent RAG), which reframes the RAG pipeline as a cooperative system of interacting agents. Each agent is responsible for different aspects of the information retrieval and reasoning process.
The Problems Agentic RAG Addresses
- Single-pass reasoning
Traditional RAG pipelines are largely single-pass (retrieve, use, generate). This is limiting when the query requires decomposition and deeper understanding. - Lack of modularity and transparency
In standard RAG, it’s hard to pinpoint where the system failed, whether it was the retriever, the reader, or the generator. Agentic RAG introduces specialized roles (e.g., retriever, verifier, planner), making the system more transparent. - Poor handling of noisy or conflicting information
Rather than blindly using retrieved documents, agents in a multi-agent setup can challenge, verify, or reject unreliable information.
How Agentic RAG Solves These Problems
Agentic RAG organizes the workflow as an interactive dialogue between cooperating agents, each contributing to the task in a structured, iterative way. Here’s how the architecture typically works:
- Role-based Decomposition of Tasks
The system can assign different responsibilities to different agents, e.g.
• a query analyzer agent which breaks down the user query into subtasks
• a generator agent which proposes candidate answers
• agent which verifies the factual consistency of outputs etc… - Iterative Interaction and Reasoning
Agents communicate in multiple iterations. They can ask clarifying questions, refine their input, or request additional retrievals. This enables self-correction and collaborative reasoning over retrieved knowledge. - Explicit Verification and Consensus
Before a final answer is given, verifier agents question the response and identify hallucinations. This internal review process increases factuality and confidence especially when dealing with conflicting or ambiguous information.A visual representation of Agentic RAG can be found in the Survey on Agentic RAG:

How to Use These Insights
To apply Agentic RAG principles in your own system:
- Simulate agents via prompting
You can create distinct agent behaviors using role-specific prompts (e.g., “You are a retriever…”, “You are a fact-checker…”). These can run sequentially or via prompt chaining. - Introduce internal dialogue or feedback loops
Add intermediate steps where the model critiques or revises its answers before final output, i.e. simulating multi-agent collaboration without needing separate models. - Build agent workflows using orchestration frameworks
Frameworks like LangChain, CrewAI or Semantic Kernel allow you to define custom agents and route interactions between them. - Isolate and evaluate agent performance
Just as in modular software, you can monitor and improve each agent independently.
Interested in this topic? Find out more at:
What is Agentic RAG? – GeeksforGeeks
[2501.09136] Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
Agentic RAG – Huggingface
If you’d like to explore additional studies on improvements in RAG, please see the following links:
Retrieval-Augmented Generation (RAG): Recent Research and Challenges
Four retrieval techniques to improve RAG you need to know | Thoughtworks
Advancements in RAG: A Comprehensive Survey of Techniques and Applications | by Sahin Ahmed, Data Scientist | Medium
